Confidence Intervals Explained
A confidence interval (CI) is a set of numbers that most likely contains the value of an unknown population parameter.
Given the properties of your sample data, these intervals represent a realistic domain for the parameter. Confidence intervals are produced using a defined confidence level and are derived from sample statistics.
Because it is nearly hard to assess entire populations, population parameters are frequently unknown. These parameters can be estimated using a sample.
However, due to random sampling error, the estimations rarely match the parameter exactly.
Inferential statistics approaches, on the other hand, can analyze a sample and account for the uncertainty that comes with employing samples.
eXtreme Gradient Boosting in R » Ultimate Guide » finnstats
Confidence intervals surround a point estimate with a margin of uncertainty to help us understand how far off the estimate might be.
Confidence intervals are routinely used to bound the sample mean and standard deviation parameters.
You can also use them to calculate regression coefficients, proportions, occurrence rates (Poisson), and population differences.
What is the Confidence Level?
The confidence level is the long-run likelihood that a set of confidence intervals will include the population parameter’s true value.
The intervals produced by different random samples selected from the same population are likely to differ slightly.
If you take a lot of random samples and calculate a confidence interval for each one, you’ll find that a certain number of them have the parameter.
Confidence Intervals Explained and How to Interpret Them
A confidence interval indicates the range of possibilities for a population parameter. For instance, a 95% confidence interval of the mean [10, 20] indicates that you may be 95% convinced that the population means is between 10 and 20.
Confidence intervals can also be used to navigate the uncertainty surrounding a sample’s capacity to reliably estimate a value for the entire population.
The sample’s point estimate is used to create these intervals, which are then multiplied by a margin of error. The point estimate is the most accurate way to estimate the parameter value.
The margin of error accounts for the uncertainty inherent when using a sample to estimate a full population.
The precision is revealed by the width of the confidence interval around the point estimate.
When the range is narrow, the margin of error is small, and the possible values are limited. That’s a very accurate assessment.
If the interval is vast, however, the margin of error is large, and the actual parameter value is likely to lie somewhere within that larger range. That is a rough estimate.
Simple Linear Regression in r » Guide » finnstats
A tight confidence interval is ideal because it will give you a much better picture of the actual population value.
Consider the following scenario: we have two separate samples with a sample mean of ten.
Both estimations appear to be accurate. Let’s look at the 95% confidence intervals now.
The first interval is [6 18], whereas the second interval is [9 12]. The second range is narrower, implying a more accurate assessment.
Confidence Intervals for Effect Sizes
Confidence intervals are also useful for determining the extent of an effect. When evaluating a treatment and control group, for example, the estimated effect size is the mean difference between the two groups.
A confidence interval for the mean difference can be constructed using a two-sample t-test.
Avoid a Common Misinterpretation of Confidence Intervals
The use of confidence intervals to the distribution of sample values is a common blunder. It’s important to remember that these ranges only relate to population factors, not data values.
A 95 percent confidence interval [10 15], for example, means that we may be 95 percent confident that the parameter is inside that range.
A 95% confidence interval is a range of values that you can be 95% certain contains the true mean of the population.
It does not, however, imply that 95 percent of the sample values fall inside that range.
Use a tolerance interval instead of a sample to find the proportion of data values that are likely to fall inside a range.
What Affects the Widths of Confidence Intervals?
So you want narrower CIs since they are more precise. What factors cause tighter ranges?
The widths of confidence intervals are affected by sample size, variability, and confidence level. The first two are sample characteristics.
Variability in Samples
The precision of the estimate is influenced by the variability in your data. When your sample standard deviation is high, your confidence intervals will be wider.
When you think about it, it makes logic. When your sample contains a lot of variabilities, you’ll be less confident in the estimations it generates.
After all, a large standard deviation indicates that your sample data is jumping around a lot! This isn’t conducive to obtaining accurate estimations.
Unfortunately, data unpredictability is often beyond your control. After then, you’re at the mercy of the inherent variability in your subject area.
You can adopt measurement and data collection processes that limit external sources of variability, but you’re still at the mercy of the variability inherent in your subject area.
However, reducing external sources of variance will aid in narrowing the width of your confidence intervals.
Sample Size
Because you can control it more than the variability in most circumstances, increasing your sample size is the most effective strategy to lower the widths of confidence intervals.
The ranges tend to shorten if you don’t do anything else than increase the sample size. Do you require even more stringent CIs? Simply increase the sample size again!
There is no theoretical limit, and you can substantially increase the sample size to generate incredibly narrow ranges.
However, in the real world, logistics, time, and expense constraints will limit your maximum sample size.
Larger sample numbers and lesser variability limit the margin of error around the point estimate, resulting in narrower confidence intervals.
The breadth of the confidence interval is likewise affected by changing the confidence level.
This component, on the other hand, is a technique choice unrelated to the features of your sample.
Predictive Analytics Models in R » finnstats
The confidence interval widens when the confidence level rises (e.g., from 95% to 99%) while the sample size and variability remain constant.
Reducing the confidence level (for example, from 95 percent to 90 percent) narrows the range.
Confidence Interval Formula
If n≥ 30 Confidence Interval = x̄ ± zα/2(σ/√n)
If n<30 Confidence Interval = x̄ ± tα/2(S/√n)
How to Find a Confidence Interval
However, imagine we have only the following summary information instead of the dataset.
Sample mean: 225
Standard deviation: 110
Sample Size: 25
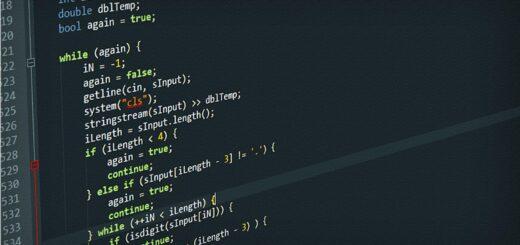
n <- 25 xbar <- 225 s <- 110 #calculate margin of error margin <- qt(0.975,df=n-1)*s/sqrt(n) #calculate lower and upper bounds of confidence interval low <- xbar - margin low [1] 179.5942 high <- xbar + margin high [1] 270.4058
The 95 percent confidence interval for the mean is 179.5–270.4. We have a 95% confidence level that the population means is inside this range.



Hey guys,
good that you try to explain an actually rather difficult concept.
In general I think though, that when expaining confidence intervals it
is a good idea to distinguish between the confidence interval as
random quantity and the confidence interval as fixed when looking at a
sample at hand.
For example your first sentence “A confidence interval (CI) is a set
of numbers that most likely contains the value of an unknown
population parameter.” Only makes sense when treating it as
random. For every realized CI the probability that the true value is
covered is either 1 or 0. As a side note: If the true value is covered
“most likely” depends on the significance level. A 50% CI does not
cover the true value most likely.
And your second sentence: “Given the properties of your sample data,
these intervals represent a realistic domain for the parameter. ” Why
do you think that? A CI might contain deeply unrealistic
values. Consider for example a CI with coverage probabilty 99.9%.
I also think trying to explain what a CI means by using words like
“confident” or “convinced” or “certain” does not help because it is
not clear what that means.
Then there are many sentences I do not understand or that are
misleading. Many seem to be just wrong. For example: “A tight
confidence interval is ideal because it will give you a much better
picture of the actual population value.” This is only true if the
point estimate is unbiased.