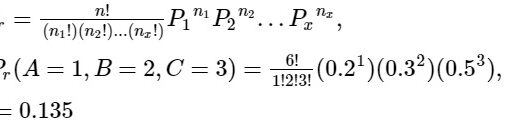Nonlinear Regression Analysis in R
Nonlinear Regression Analysis in R, when at least one of the parameters in a regression appears to be nonlinear, it is called nonlinear regression.
It is often used to sort and analyze data from many businesses, such as retail and banking.
It also aids in drawing conclusions and forecasting future trends based on the user’s online behavior.
The process of creating a nonlinear function in R is known as nonlinear regression analysis. This approach uses independent factors to predict the result of a dependent variable using model parameters that are depending on the degree of association between variables.
When the variance in sample data is not constant or when errors are not normally distributed, generalized linear models (GLMs) calculate nonlinear regression.
When the following sorts of regressions are regularly used, a generalized linear model is used.
Proportions are used to express count data (e.g. logistic regressions).
Data is not expressed as proportions when it is counted (e.g. log-linear models of counts).
Binary response variables exist (for example, “yes/no,” “day/night,” “sleep/awake,” and “purchase/not buy”).
The data shows that the coefficient of variation is constant (e.g. time data with gamma errors).
Nonlinear Regression Analysis in R
One of the most prevalent types of nonlinear regression in statistics is logistic regression. It’s a method for estimating the likelihood of an occurrence based on one or more independent factors.
Using probability theory, logistic regression determines the associations between the listed factors and independent variables.
Logistic Regression is a technique for predicting the outcome of In circumstances where the rate of growth does not remain constant throughout time, models are commonly used.
For example, when a new technology is first brought to the market, its demand rises quickly at first, but then progressively declines.
Logistic regression is defined using logit() function:
f(x) = logit(x) = log(x/(1-x))
Assume that p(x) indicates the probability of an event, such as diabetes, occurring based on an independent variable, such as a person’s age. The following will be the probability p(x).
P(x)=exp(β0+ β1x1 )/(1+ exp(β0+ β1x1)))
Here β is a regression coefficient.
We obtain the following when we take the logit of the previous equation.
logit(P(x))=log(1/(1-P(x)))
When we solve the equation above, we get.
logit(P(x))=β0+ β1x1
The Sigmoid Function is a logistic function that is represented by an S-shaped curve.
When a new technology is introduced to the market, demand typically rises quickly in the initial few months before progressively declining over time.
This is a case of logistic regression in action. In circumstances where the rate of growth does not remain constant over time, Logistic Regression Models are commonly used.
Multivariate logit() Function
In the case of several predictor variables, the logistic function is represented by the following equation.
p = exp(β0+ β1x1+ β2x2+—– βnxn)/(1+exp(β0+ β1x1+ β2x2+…+βnxn))
The predicted probability is p, the independent variables are x1,x2,x3,…,xn, and the regression coefficients are 0, 1, 2,…n.
Manually estimating coefficients is a time-consuming and error-prone technique that requires numerous difficult and lengthy calculations.
As a result, sophisticated statistical software is typically used to make such estimates. In statistical analysis, coefficients must be calculated.
A relationship between three or more variables that specify the simultaneous influence of two or more interacting variables on a dependent variable is known as interaction.
We can use interacting variables to calculate logistic regression with three or more variables in a relationship where two or more independent factors influence the dependent variable.
An enumerated variable in logistic regression can have an order but not a magnitude. Because arrays have both order and magnitude, they are inappropriate for storing enumerated variables.
Dummy or indicator variables are used to store enumerated variables. There are two possible values for these dummy or indicator variables: 0 and 1.
You must test the accuracy of a Logistic Regression Model’s predictions after it has been developed. The following are some examples of adequacy checking techniques:
Residual Deviance – A high residual variation indicates that the Logistic Regression Model is insufficient. The best value for the Logistic Regression Model’s residual variance is 0.
Parsimony – Logistic Regression Models with fewer explanatory variables are more reliable and can also be more valuable than models with a high number of explanatory variables.
The process of determining the threshold probability for a response variable based on explanatory variables is referred to as classification accuracy. It makes it simple to understand the results of a Logistic Regression Model.
Cross-validation is used to check the accuracy of predictions for the Logistic Regression Model, and it is repeated numerous times to increase the Logistic Regression Model’s prediction accuracy.
Applications:
Loan Acceptance – Organizations that provide banks or loans can use logistic regression to evaluate if a consumer would accept a loan offered to them based on their previous behavior.
Customer age, experience, income, family size, CCAvg, Mortgage, and other explanatory variables are among the several explanatory variables.
Delayed Airplanes – A likely delay in flight timing can also be predicted using logistic regression analysis. Different arrival airports, varied departure airports, carriers, weather conditions, the day of the week, and a categorical variable for different departure hours are all explanatory variables.
MLE-based line estimation
The parameter values that appear in the regression model are used to construct regression lines for models. As a result, you must first estimate the regression model’s parameters. To improve the accuracy of linear and nonlinear statistical models, parameter estimation is used.
Maximum Likelihood Estimation is a method for estimating the parameters of a regression model (MLE).
Nonlinear regression in action: This example is based on the link between the length of a deer’s jaw bone and its age.
The dataset is read from the jaws.txt file; the file’s path is used as a parameter.
deer<-read.table("E:\Website\Images\jaws.txt",header=T)You can download the dataset from here – jaws file
Getting the model to fit — The nls() command accepts a nonlinear equation as an argument with beginning values for the a, b, and c parameters. The outcome is saved in the model object.
bone<-deer$bone age<-deer$age model1<-nls(bone~a-b*exp(-c*age),start=list(a=120,b=110,c=0.064))
The summary() command is used to display information about a model object. As demonstrated below, the model object is passed as a parameter to the summary() command:
summary(model1)
Formula: bone ~ a - b * exp(-c * age) Parameters: Estimate Std. Error t value Pr(>|t|) a 115.2528 2.9139 39.55 < 2e-16 *** b 118.6875 7.8925 15.04 < 2e-16 *** c 0.1235 0.0171 7.22 2.44e-09 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 13.21 on 51 degrees of freedom Number of iterations to convergence: 5 Achieved convergence tolerance: 2.383e-06
For the changed regression model, use the nls() command on the new model. The outcome is saved in the model2 object.
model2<-nls(bone~a*(1-exp(-c*age)),start=list(a=120,c=0.064))
When comparing the models, keep the following in mind: To compare the output objectsmodel1 and model2, use the anova() tool. These items are then passed to the anova() command as parameters.
anova(model1,model2)
Analysis of Variance Table
Model 1: bone ~ a - b * exp(-c * age) Model 2: bone ~ a * (1 - exp(-c * age)) Res.Df Res.Sum Sq Df Sum Sq F value Pr(>F) 1 51 8897.3 2 52 8929.1 -1 -31.843 0.1825 0.671
Taking a look at the New Model2’s components
summary(model2)
Formula: bone ~ a * (1 - exp(-c * age)) Parameters: Estimate Std. Error t value Pr(>|t|) a 115.58056 2.84365 40.645 < 2e-16 *** c 0.11882 0.01233 9.635 3.69e-13 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 13.1 on 52 degrees of freedom Number of iterations to convergence: 5 Achieved convergence tolerance: 1.369e-06
Summary
In R programming, we learned the entire notion of nonlinear regression analysis. We learned about R logistic regression and its applications, as well as MLE line estimation and R nonlinear regression models.
Note:
Models with Generalized Additive Functions (GAM)
We can see that the relationship between y and x is nonlinear at times, but we don’t have any theory or mechanical model to suggest a specific functional form (mathematical equation) to represent it.
Generalized Additive Models (GAMs) are particularly beneficial in these situations since they fit a nonparametric curve to the data without asking us to specify a mathematical model to characterise the nonlinearity.
GAMs are valuable because they allow you to figure out the relationship between y and x without having to choose a specific parametric form. The function gam() command in R implements generalised additive models.
Many of the features of both glm() and lm() are present in the gam() command, and the result can be modified using the update() command.
After a GAM has been fitted to data, you can use all of the standard methods including print, plot, summary, anova, forecast, and fitted. The mgcv library includes the gam function.