Sample and Population Variance in R
Sample and Population Variance in R, The variance is a metric for determining how dispersed data values are around the mean.
Variance is the expectation of a random variable’s squared departure from its mean in probability theory and statistics, and it informally indicates how far a set of (random) values is spread out from its mean.
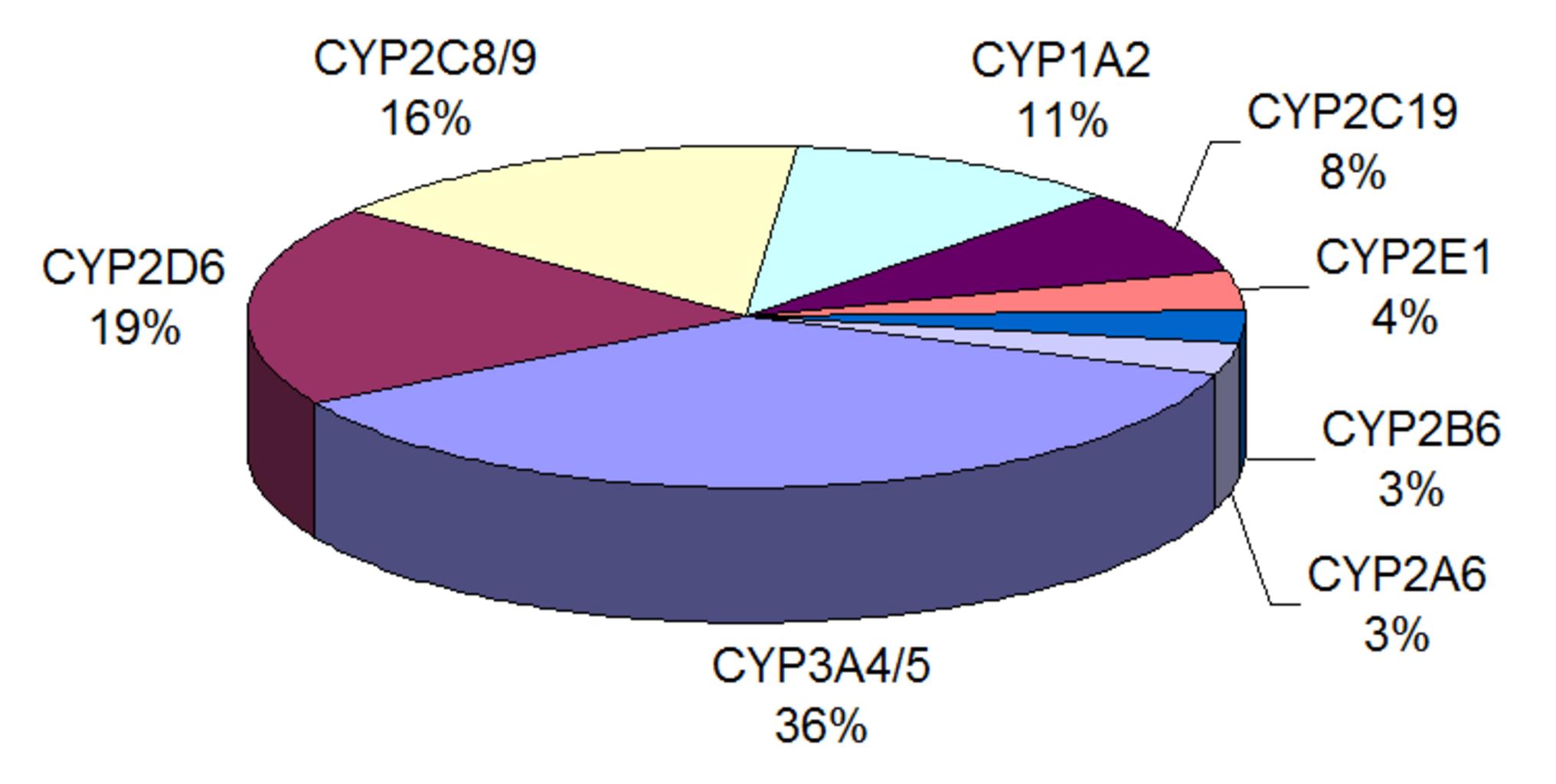
The formula for calculating a population’s variance is
σ2 = Σ (xi – μ)2 / N
where μ is the population mean, xi is the ith population element, N is the population size, and is basically Σ a fancy symbol for “sum.”
To determine a sample’s variance, use the following formula:
s2 = Σ (xi – xbar)2 / (n-1)
where xbar represents the sample mean, xi represents the sample’s ith element, and n represents the sample size.
Calculate Sample & Population Variance in R
Assume we have the following R dataset and stored in data1.
Let’s create a data set values
data1<- c(12,84, 5, 17, 18, 11, 13, 19, 69, 92,15,10,55)
The var() function in R can be used to calculate sample variance.
Let’s calculate the sample variance
var(data1) 957.8974
The population variance can be calculated by multiplying the sample variance by (n-1)/n as follows.
Now we can calculate the length of the data1
n <- length(data1) n 13
It’s ready to find population variance
var(data1) * (n-1)/n 884.213
It’s important to remember that the population variance is always lower than the sample variance.
In practice, we calculate sample variances for datasets because collecting data for a whole population is uncommon.
Calculate the Sample Variance of Multiple Columns as an example
Let’s say we have the following R data frame:
Now we can create a data frame
data2 <- data.frame(X=c(12, 35, 55, 48, 54, 12, 8, 10), Y=c(12, 24, 33, 77, 5, 46, 71, 106), Z=c(1, 2, 63, 8, 12, 77, 92, 102)) data2
X Y Z 1 12 12 1 2 35 24 2 3 55 33 63 4 48 77 8 5 54 5 12 6 12 46 77 7 8 71 92 8 10 106 102
To determine the sample variance of each column in the data frame, we can use the sapply() function:
Yes, now based on sapply we can find each column’s sample variance.
sapply(data2, var)
X Y Z 439.6429 1238.7857 1863.9821
We can also determine the sample standard deviation of each column using the following code, which is essentially the square root of the sample variance:
To find each column’s sample standard deviation
sapply(data2, sd) X Y Z 20.96766 35.19639 43.17386
When it comes to data analysis, Sapply is a highly handy function.
Stringr in r 10 data manipulation Tips and Tricks » finnstats