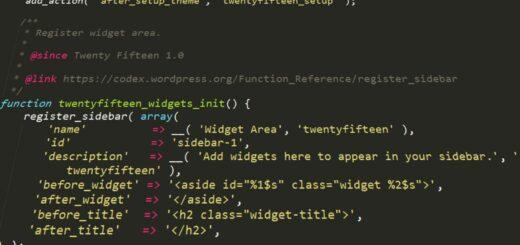
Anderson-Darling Test in R (Quick Normality Check)
Anderson-Darling Test in R, The Anderson-Darling Test is a goodness-of-fit test that determines how well your data fits a given distribution.
This test is most typically used to see if your data follow a normal distribution or not.
This sort of test can be used to check for normality, which is a common assumption in many statistical tests such as regression, ANOVA, and t-tests.
Calculates the Anderson–Darling test statistic for a sample chosen from a specified distribution and determines whether to reject or accept the hypothesis that the sample was drawn from that distribution.
How to Calculate Phi Coefficient in R » Association »
Anderson-Darling Test in R
For the composite hypothesis of normality, the Anderson-Darling test is used.
Syntax:-
ad.test(x)
x:- a numeric vector of data items with a length greater than seven. Values that are missing are acceptable.
The ad.test() function in the nortest package can be used to perform an Anderson-Darling Test in R.
Log Rank Test in R-Survival Curve Comparison »
If you don’t already have yet installed it, run the command below to install the package and load the nortest library.
install.packages('nortest')
library(nortest)Example 1:- mtcars dataset
In R, we can also do an AD-test on a single column of a data frame. Take, for example, the built-in mtcars dataset.
view first six lines of mtcars dataset
head(mtcars)
mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1 Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2 Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
Let’s say we want to see if the variable mpg is normally distributed or not. To visualize the distribution of values, we may first generate a histogram.
hist(mtcars$mpg, col = 'red', main = 'Distribution of mpg',xlab = 'MPG')
Distribution of mpg in mtcars dataset in R
How to Identify Outliers-Grubbs’ Test in R »

The data appears to be evenly dispersed. We may use an A-D test to formally check whether the data is normally distributed to confirm this.
conduct Anderson-Darling Test to test for normality
ad.test(mtcars$mpg)
Anderson-Darling normality test data: mtcars$mpg A = 0.57968, p-value = 0.1207
We don’t have enough evidence to reject the null hypothesis and infer that mpg follows a normal distribution because the test’s p-value is bigger than 0.05.
Introduction to Deep Learning »