Box Plot Graph in R Language
Box Plot Graph in R Language, we will demonstrate how to make a box plot in the R programming language. A box plot summarises the distribution of numerical data that has been sorted.
The first quartile is located 25% of the way through the sorted data. In other words, one-quarter of the data points have a value smaller than this.
Likewise, 75% of the points are fewer than the third quartile value. Simply said, the interquartile range is the difference between the first and third quartiles.
The median corresponds to the second quartile. As a result, 50% of the data falls below the median.
The lower and upper whiskers represent values that are outside the interquartile range. Then there’s the mean, or average, of all the data points.
KNN Algorithm Machine Learning » Classification & Regression »
Example
Let’s take a look at a real-world example to understand how this works.
The following data set is available:
77, 79, 80, 86, 87, 87, 94, 99
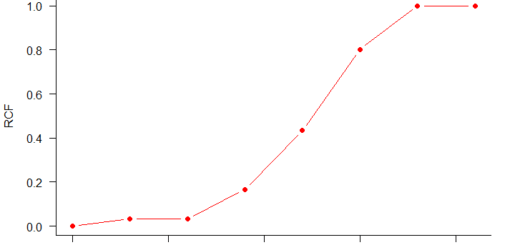
Median =(86+87)/2=86.5
First Quartile=Q1= (79+80)/2=79.5
Third Quartile=Q3=(87+94)/2=90.5
Lower Whisker=77
Upper whisker=99
Because the dataset comprises eight values, we’ll add the fourth and fifth items and divide them by two to determine the median.
Take note of how half of the elements are less than the median and the other half are greater. A similar formula can be used to get the first and third quartiles.
Principal component analysis (PCA) in R »
Two of the eight elements are less than the first quartile, while six of the eight elements are less than the third quartile. And the whiskers at the bottom and top just stretch to the minimum and maximum values.
Box plot Graph in R
We’ll use the normal distribution to generate a collection of pseudo-random data points for our box plot.
To repeat the results, we’ll change the seed value for the random number generator. As a result, the data will appear random, but it will be the same each time the code is executed.
set.seed(123)
Then we’ll make two data sets, A and B, each with 300 samples.
Set A is drawn from a normal distribution with a mean of one and a standard deviation of two.
summarize in r, Data Summarization In R »
Set B has a mean of 0 and a standard deviation of 1.
A<-rnorm(300, mean=1,sd=2) B<-rnorm(300, mean=0,sd=1)
We’ll put these sets into a data frame, separating them by the label.
Let’s create a data frame.
DF<-data.frame(label=factor(rep(c("A","B"),each=300)),value=c(A,B))
head(DF)label value 1 A -0.1209513 2 A 0.5396450 3 A 4.1174166 4 A 1.1410168 5 A 1.2585755 6 A 4.4301300
Take note of how the numbers are clustered together based on their original set.
Stringr in r 10 data manipulation Tips and Tricks »
We’ll be employing the ggplot2
library(ggplot2)
You can use ggplot2 to generate highly customizable and aesthetically beautiful data visualizations.
We’ll use the code below to generate a box plot using the data sets.
ggplot(DF,aes(x=label,y=value))+geom_boxplot()
We’ll execute the ggplot method with our data frame as input, displaying the labels on the x-axis and the range of values on the y axis.
We need to add the “geom boxplot” method at the end to get a box plot as output.

Values greater than 1.5 times the interquartile range are considered outliers in the whiskers. These are denoted by dots.
apply family in r apply(), lapply(), sapply(), mapply() and tapply() »
Let’s get started with the real-world mtcars dataset, which contains information about automobiles from 1973 to 1974.
summary(mtcars)
Because the dataset is built into R, you may begin referencing it in your code right now without using any import statements.
We’ll focus on the first two variables in the top row: miles per gallon and cylinder count. First, we’ll make a box plot with qplot.
qplot(factor(cyl),mpg, data=mtcars, geom="boxplot")
qplot is a basic function in the ggplot2 package that is easy to use while still producing evocative graphs.
The number of cylinders will be displayed on the x-axis.
We’ll use the “factor” function because the number of cylinders is more of a category than a numerical feature.
The engines are either four-cylinder, six-cylinder, or eight-cylinder.
How to measure the association between the ranks? »
We’ll utilize the miles per gallon data for the y axis.
The dataset we’re using is mtcars, and we need to mention that we’re making a box plot for the geometry.
And as you can see, a box plot is generated for each cylinder category.

You may even detect a correlation between cylinder count and miles per gallon.
We may alternatively use the more configurable ggplot tool.
plot3<-ggplot(mtcars, aes(factor(cyl),mpg))plot3+geom_boxplot()

The second option, aes, represents a list of aesthetic mappings between data variables and visual qualities.
We’ll look at how “cylinder count” relates to “miles per gallon” once more.
We may examine the box plot in the output after adding the “geom boxplot” method.
You should now understand the structure of a box plot and how to make one in the R computer language.