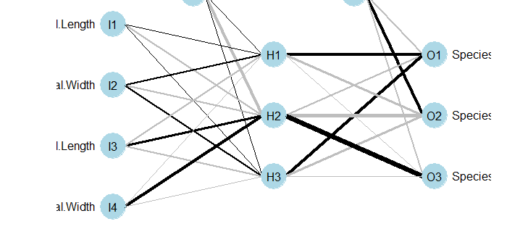
Random Forest Model in R
The random forest model in R is a highly useful tool in analyzing predicted outcomes for a classification or regression model.
The main idea is how explanatory variables will impact the dependent variable.
In this particular example, we analyze the impact of explanatory variables of Attribute 1, Attribute2, …Attribute6 on the dependent variable Likeability.
What are the Nonparametric tests? » Why, When and Methods »
Data Loading
Use read.xlsx function to read data into R.
data<-read.xlsx("D:/rawdata.xlsx",sheetName="Sheet1")We then split the data set into two training dataset and test data set. Training data that we will use to create our model and then the test data we will test it.
We have randomly created a data frame with a total of 64 data row observations, 60 observations used for training the data set, and 4 observations used for testing purposes.

#Create training and test data
inputData <- data[1:60, ] # training data testData <- data[20:64, ] # test data
While using tuneRF function we can find out best mtr
tuneRF(data2,data2[,dim(data2)[2]], stepFactor=1.5) mtry = 8 provides best OOB error = 0.01384072

A random forest allows us to determine the most important predictors across the explanatory variables by generating many decision trees and then ranking the variables by importance.
How to run R code in PyCharm? » R & PyCharm »
Random Forest Model in R
AttribImp.rf<-randomForest(Likeabilty~.,data=data2,importance=TRUE,proximity=TRUE, ntree=100, mtry=8, plot=FALSE) print(AttribImp.rf)
Type of random forest: regression Number of trees: 100 No. of variables tried at each split: 8 Mean of squared residuals: 2.00039 % Var explained: 78.58
Basis just 60 data points we 79% variance explained, recommended minimum 100 data points in each model for an accurate result.
LSTM Network in R » Recurrent Neural network »
Using the Boruta algorithm we can easily find out important attributes in the model.
Important <- Boruta(Likeabilty~ ., data = data2) print(Important)
Boruta performed 87 iterations in 1.140375 secs.
5 attributes confirmed important: Attribute2, Attribute3, Attribute4, Attribute6,
Panel: 2 attributes confirmed unimportant: Attribute1, Attribute5;
Predict test data based on the training model
testData1<-testData[,-dim(testData)[2]] preddiction<-predict(AttribImp.rf,testData1) print(prediction)
The predicted values are 4, 4, 5, 5, 4 and the original values are 2, 2, 2, 3, 4, Yes, it’s just close not good.
Recommended to increase the number of data points and increase the model accuracy 79 to at least 85.
Log Rank Test in R-Survival Curve Comparison »