Sampling from the population in R
Sampling from the population in R, Imagine you were requested to contribute to the creation of a travel guideline for New York City-based business travellers.
Imagine that the traveller will be meeting at the designated time “t” in San Francisco.
The next rules will outline how much sooner than “t” an acceptable flight should arrive in order to prevent missing the meeting because of a delayed trip.
We’ll presume for the sake of this example that we already have the entire set of population flights in hand.
In order to achieve this, we’ll be using the collection of 336776 flights from New York City airports in 2013 from the nycflights13 package.
We will create a policy for 2013 alone. This is obviously unrealistic in real life. We could easily find the best aircraft that arrived in time for the conference if we had the entire population.
The issue would more specifically be how to create a policy for 2013 based on the sample of data that has already been gathered.
By selecting a sample from the overall flight population at SFO, we will mimic this scenario.
In our little play, SF represents the population and consists of the entire collection of such flights.
library(mdsr) library(ggplot2) library(nycflights13) library(dplyr) SF<-flights %>% filter(dest=="SFO", is.na(arr_delay))
We’ll just use a sample of this population for our work. We’ll choose n=30 as the sample size for the time being.
set.seed(123) Sample30<-SF %>% sample_n(size=30)
Finding the flight with the longest delay and requiring that travel arrangements be made to accommodate it are two straightforward ways to establish the policy.
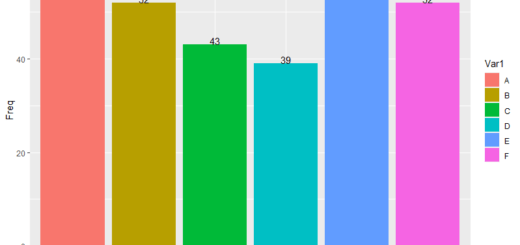
favstats(~arr_delay,data=Sample30) min Q1 median Q3 max mean sd n missing -39 -13 12.5 42 285 26.53333 64.99482 30 0
285 minutes is the maximum delay. Therefore, should our travel policy state that travellers should allow at least two hours to reach SFO? In our hypothetical scenario, we can examine all of the flights to determine the worst delay that actually occurred in 2013.
Free Data Science Books » EBooks »
favstats(~arr_delay,data=SF) min Q1 median Q3 max mean sd n missing -86 -23 -8 12 1007 2.672892 47.67064 13173 0
The delay is roughly 2.67 hours when compared to the population’s completely different picture.
A sensible travel policy will weigh the modest chances of running late against the money and time saved.
For example, you might consider it acceptable to arrive late only 2% of the time and 98% of the time.
qdata(~arr_delay,p=0.98,data=Sample30) 98% 199.16
A delay of 200 minutes. How good is this answer?
tally(~arr_delay<90, data=SF, format="proportion") arr_delay < 90 TRUE FALSE 0.95141577 0.04858423
It would be far worse than we expected for the 90-minute policy to miss its mark 5% of the time. We will wish to raise the policy from 90 minutes to what value in order to appropriately hit the mark 2% of the time.
qdata(~arr_delay, p=0.98, data=SF) 98% 153
Instead of 90 minutes, it should have been around 150 minutes. We lack access to the population data, however, in many significant real-world scenarios. We only have a sample.

Now retrieving an image set.