Process of Machine Learning Optimisation?
Process of Machine Learning Optimisation?, Algorithms and statistical models are employed in the branch of artificial intelligence known as machine learning to assist computers in learning from data and making predictions or judgments without the need for explicit programming.
A crucial step in the development of machine learning algorithms is the identification of the optimal values of the parameters that minimize or maximize a specific objective function.
This article will discuss the role of optimization in machine learning and its importance for creating machine learning models.
What does machine learning optimization mean?
The process of finding the perfect collection of model parameters that minimize a loss function is known as optimization in machine learning.
The loss function determines the difference between the predicted and actual outputs for a specific set of inputs.
The goal of optimization is to reduce the loss function in order to enable the model to accurately predict the output for new inputs.
An optimization algorithm is a technique used in optimization that determines the lowest or maximum of a function.
The optimization process iteratively alters the model parameters until it reaches the minimum or maximum of the loss function.
The optimization techniques Adam, Adagrad, stochastic gradient descent, gradient descent, and RMSProp can all be used in machine learning.
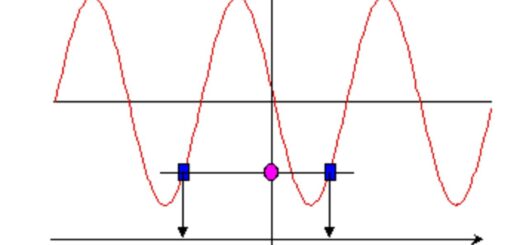
Gradient Descent
Gradient descent is a well-liked optimization technique in machine learning. It is a first-order optimization algorithm that operates by continually altering the model’s parameters in the direction that is the inverse of the negative gradient of the loss function.
Because the negative gradient leads in the direction of the greatest drop, the loss function decreases most quickly in that direction.
When using a set of initial parameters, the gradient descent algorithm calculates the gradient of the loss function with respect to each parameter.
The gradient is a vector that contains the partial derivatives of the loss function with respect to each parameter.
The method then adjusts the parameters by subtracting from their current values a small multiple of the gradient.
Random Gradient Descent
The stochastic gradient descent procedure, which is a modification of the gradient descent technique, randomly selects a portion of the training data for each iteration.
This simplifies the algorithm’s calculations and accelerates convergence. Stochastic gradient descent is particularly useful for large datasets when it is not practicable to compute the gradient of the loss function for all of the training data.
Stochastic gradient descent differs from gradient descent in that it modifies the parameters based on the gradient derived for a single case rather than the entire dataset.
This introduces stochasticity into the process, which could lead to a different local minimum in each iteration.
Adam
Adam is an optimization algorithm that combines the benefits of stochastic gradient descent and momentum-based methods.
The first and second moments of the gradient are used to adaptively alter the learning rate during training.
Since Adam is known to converge more quickly than other optimization approaches, it is commonly utilized in deep learning.
Adagrad
Based on past gradient data, the Adagrad optimization method modifies the learning rate for each parameter.
For sparse datasets with intermittent occurrences of particular attributes, it is extremely useful.
Because Adagrad uses distinct learning rates for each parameter, it can converge more fast than other optimization techniques.
RMSProp
The problem of exploding and disappearing deep neural network gradients is addressed with an optimization technique known as RMSProp.
The learning rate for each parameter is normalized using the moving average of the squared gradient.
It is commonly known that the well-liked deep learning optimization technique RMSProp converges faster than certain other algorithms.
Optimization’s importance in machine learning
Since optimization enables the model to learn from data and produce accurate predictions, machine learning largely relies on it.
Observed data is used to estimate model parameters using machine learning techniques.
The process of optimization involves determining the parameters’ ideal values to reduce the difference between the expected and actual results for a certain set of inputs.
Without optimization, the parameters of the model would be selected at random, making it impossible to predict the result accurately for novel inputs.
Deep learning models, which include a multitude of layers and millions of parameters, place a high priority on optimization.
To optimize the parameters of the model in which they are utilized, deep neural networks need a lot of processing power and a lot of data to be trained.
The accuracy and speed of the training process can be significantly impacted by the optimization method employed.
Additionally, only optimization is used to develop new machine-learning algorithms.
To increase the precision and speed of machine learning systems, researchers are continually exploring for new optimization strategies.
These methods include normalization, optimization tactics that take into consideration an understanding of the data’s underlying structure, and adaptive learning rates.
Problems with Optimisation
The optimization of machine learning is not without its challenges. Overfitting, which occurs when a model learns the training data too well and is unable to generalize to new data, is one of the most challenging problems.
Overfitting may occur when the model is extremely complex or the training set is insufficient.
Another challenge in optimization is the issue of local minima, which arises when the optimization process converges to a local minimum rather than the global optimum.
Local minima are quite common in deep neural networks, which have many parameters and may have multiple local minima.
Conclusion
In conclusion, one of the most important tasks of machine learning algorithms is determining the best choices for model parameters that minimize a loss function.
Machine learning can benefit from a variety of optimization approaches, including gradient descent, stochastic gradient descent, Adam, Adagrad, and RMSProp.
The accuracy and performance of machine learning algorithms depend heavily on optimization, especially in deep learning, where models have many layers and millions of parameters.
Local minima and overfitting are just two of the concerns that might occur during optimization.
By employing novel optimization techniques, which academics are constantly exploring, these problems can be resolved as well as the accuracy and speed of machine learning algorithms.